
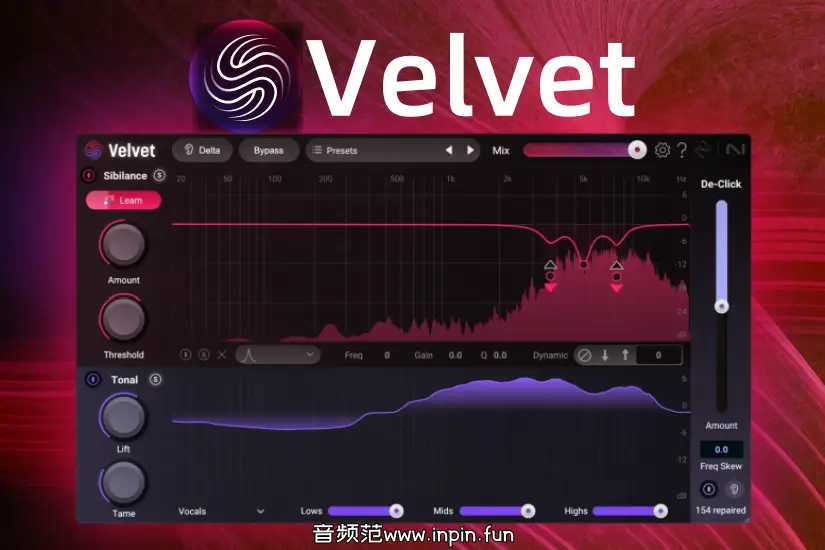
iZotope Velvet 并非虚拟乐器或音源,而是一款专业人声与对白处理插件,核心用途是对齿音、口部噪声和刺耳高频进行智能、动态的精细控制。它面向混音、后期制作与广播级音频处理场景,强调在消除问题频段的同时,最大程度保留人声的自然音色与清晰度。
该插件适用于主唱、人声叠录、对白、播客、配音以及任何对齿音控制要求较高的音频素材。
核心处理理念
齿音与音色分离处理
Velvet 的核心设计在于将输入信号拆分为两个部分:
-
Sibilance(齿音)部分:主要包含 “S”“T”“Sh”“Ch” 等高频瞬态
-
Tonal(音色)部分:人声主体的音高、共振和情感信息
通过分离处理逻辑,Velvet 可以只对齿音进行动态压制,而不会像传统去齿音器那样整体削弱高频亮度。
主要功能模块
智能动态去齿音(Dynamic De-essing)
Velvet 会自动分析音频中最刺耳的齿音区域,并在需要时动态降低其能量。处理只在齿音出现时触发,不会持续削弱高频,使人声保持通透与存在感。
自动频率学习(Learn 功能)
通过一键学习,插件可快速识别当前素材中最需要控制的齿音频段,减少手动查找频率的时间,非常适合快速混音流程。
Lift / Tame 音色控制
除了去齿音,Velvet 还允许对主体音色进行动态塑形:
-
Lift:在不放大齿音的前提下增强清晰度与存在感
-
Tame:柔和地控制过于激进或刺耳的音色成分
这种处理方式比静态 EQ 更自然,也更符合人声动态特性。
De-Click 口部噪声处理
内置的 De-Click 模块可用于减少唇齿声、口水声、轻微爆破音等细节噪声,使人声更加干净、专业,尤其适合独唱、配音和近距离录音素材。
界面与操作体验
-
齿音与音色分区显示,处理逻辑直观清晰
-
实时可视化反馈,便于观察处理强度
-
支持并行混合(Dry/Wet)控制
-
可单独监听被处理的齿音部分,便于精确调整
-
提供大量实用预设,覆盖主唱、对白、叠录人声等常见场景
整体界面设计强调“少参数、快判断”,适合快速决策型混音流程。
典型使用场景
主唱与人声混音
在不牺牲亮度与空气感的前提下,精准控制齿音,使人声在混音中更加顺滑、靠前。
对白、播客与广播制作
有效减少齿音与口部噪声,提高语音清晰度与可听性,适合长时间聆听内容。
多轨叠唱与合唱
统一控制多个声部的齿音能量,避免高频叠加导致的刺耳问题。
细节修复与精修处理
可作为传统 De-esser 的高级替代方案,用于对高质量录音进行最后的精修。
兼容性与工作流程
Velvet 作为标准音频效果插件,可直接插入人声或对白轨道,支持主流插件格式,能够无缝集成到常见 DAW 的混音与后期流程中,适合实时与离线处理。
整体特点概括
-
智能、动态的去齿音处理方式
-
齿音与主体音色分离,处理更自然
-
一键学习频率,快速上手
-
兼顾去齿音与音色塑形
-
内置 De-Click,改善口部细节
-
面向专业混音与后期应用场景
iZotope Velvet 是一款以“精细控制而非粗暴削减”为核心理念的人声处理插件,特别适合对音质要求较高的现代混音、对白与内容制作工作流。

评论0